新闻动态
News


今要求最严苛的推理负载,其特征已不再是“单一提示词 + 简短回复” 的模式,而是持久交互、多轮推理与智能体工作流。在这类负载中,海量推理历史数据需要在多轮对话、多个会话、多个智能体乃至跨多服务之间保持持续可用。
随着这类负载规模不断扩大,系统瓶颈也在随之转移。尽管 GPU 算力仍是基础,但系统整体性能越来越取决于推理的效能:在持续负载下,推理会话历史(上下文)能否被高效地存储、检索、复用与共享。
针对这一转变,在刚刚过去的 CES 2026上,英伟达正式发布面向 Rubin 平台的推理上下文内存存储(Inference Context Memory Storage,ICMS)平台。该平台将主要以 KV Cache 形式存在的推理上下文,确立为最重要的系统资源之一,并支持在 1,152 块 GPU 组成的 Pod 内实现高速访问。
当上下文数据量增长至数十万甚至数百万 token 时,推理历史数据的规模会迅速超出单台服务器的 GPU 与 CPU 内存上限。此时系统必须能够稳定、持续且无中断地管理更大的工作数据集 —— 这正是英伟达 Dynamo 这类 KV Cache 推理计算框架所要解决的核心问题。
英伟达 Dynamo 推理计算框架内置了分层式 KV Cache 块管理器,构建了一套从 GPU 内存延伸至 CPU 内存,如今又拓展至新型持久化内存层的动态缓存管理系统。
而英伟达的 ICMS 平台则采用了一种全新的高性能方案来解决迫在眉睫的容量问题:将推理上下文数据从 GPU 与 CPU 内存迁移至基于 RDMA 互连的持久化 NVMe 存储中,从而彻底打破集群内存空间对上下文大小的限制。
最终决定方案成败的关键,不仅在于能否存储上下文数据,更在于当上下文数据变得海量、共享且被持续访问时,系统能否保持稳定高效的运行状态。
传统方案的短板所在
在延迟敏感的推理场景下,数据路径中的每一个操作,都会决定系统支撑推理上下文数据服务的效能。分析当前传统存储系统的架构设计之后,就不难发现,要实现极致的首 token 响应时间(TTFT),必须从共享 KV Cache 命名空间中剔除诸多低效环节。
数据路径
由于 KV Cache 数据的检索时长是影响推理体验的核心因素,我们重点分析从共享存储中检索数据所需的时间。
传统模式下,数据从共享 SSD 传输至客户端 GPU 内存的路径,始终无法达到最优状态。这是由于传统流程中,数据通常经历多次拷贝:
SSD 数据先被拷贝至存储控制器;
再由控制器拷贝至文件服务器;
接着从文件服务器拷贝至主机 CPU 内存;
最后才从 CPU 内存拷贝至 GPU 内存。
而新技术的出现正在逐步消除这些瓶颈:
RDMA 技术,基于 NVMe-oF 可省去数据向控制器或文件服务器的拷贝步骤;
GPUDirect Storage 技术,则能省去从文件服务器到 CPU 内存的拷贝步骤,实现数据从文件服务器直接写入 GPU 内存。
传统的 GPU 直通 I/O 方式,其中数据需经由文件服务器进行拷贝。
尽管 RDMA 已能助力构建更精简的数据路径,但要让英伟达 ICMS 平台的架构性能达到极致,仍存在一次关键拷贝未被消除。
服务器资源竞争
即便完成了数据路径的优化,资源竞争问题依然存在。自分布式计算诞生以来,传统的客户端-服务器架构就决定了:大量客户端需竞争有限的共享资源池,且该架构的设计前提从未考虑过 “所有客户端同时对存储服务器进行读写操作” 的场景 —— 而这恰恰是 KV Cache 的运行模式。
因此,要构建最优的 ICMS 平台架构,就必须重新设计传统的客户端-服务器模型,确保所有主机都能同时获得对存储服务器基础设施的专属高性能访问权限。
VAST Data 带来的系统级变革
依托英伟达的加速计算与人工智能技术栈,VAST AI OS 打造出了我们迄今为止性能最强的人工智能数据系统。通过这一方案,我们能够构建具备海量扩展能力的共享 KV Cache 集群,在最大限度降低首 token 响应时间的同时,减少功耗、空间与成本投入,为英伟达 Rubin 集群提供经过优化的推理上下文内存存储方案。
VAST Data 选择以彻底重构系统架构的方式来解决这一难题。
服务器与数据路径整合
英伟达 ICMS 平台将数据管理功能直接嵌入 GPU 服务器,具体方式是让 VAST CNode 软件原生运行在节点的 BlueField-4 DPU 中。英伟达 BlueField DPU 可提供所需的 CPU 算力来运行 VAST Data 软件的全部功能模块,将数据放置决策、访问权限管控与元数据快速解析等功能,都直接部署在 GPU 主机本地,从而省去了一整排 x86 服务器的投入。如今,I/O 处理操作可在靠近推理实际运行的位置完成。
从 SSD 到 GPU 显存的无拷贝 RDMA 数据路径
VAST Data 的缓存管理引擎(CME)可将 KV Cache 相关功耗降低 75%
其次,通过省去 x86 服务器层,VAST RDMA 客户端可借助 GPUDirect Storage 技术,实现从 GPU 内存到存储或者检索 KV Cache 数据的 NVMe SSD 之间的直接零拷贝 I/O 操作。通过减少一次数据拷贝,就能进一步缩短首 token 响应时间。
CME 支持从 SSD 到 GPU 显存的零拷贝数据放置。
如何才能将服务器功能嵌入 GPU 主机,同时又不增加系统复杂度?答案在于 VAST Data 极具创新性的 DASE (分解式全共享)架构。DASE 架构支持每个 CNode 服务器容器完全并行运行,在多服务器存储环境中实现 “东西向流量” 零损耗。
与传统企业级 NAS 系统和并行文件系统不同,DASE 架构中没有任何服务器会独占文件系统存储设备的某个分区,因此在大型 GPU 集群中,每台主机都能拥有专属的文件服务器,且不会受到其他主机上文件服务器的干扰。
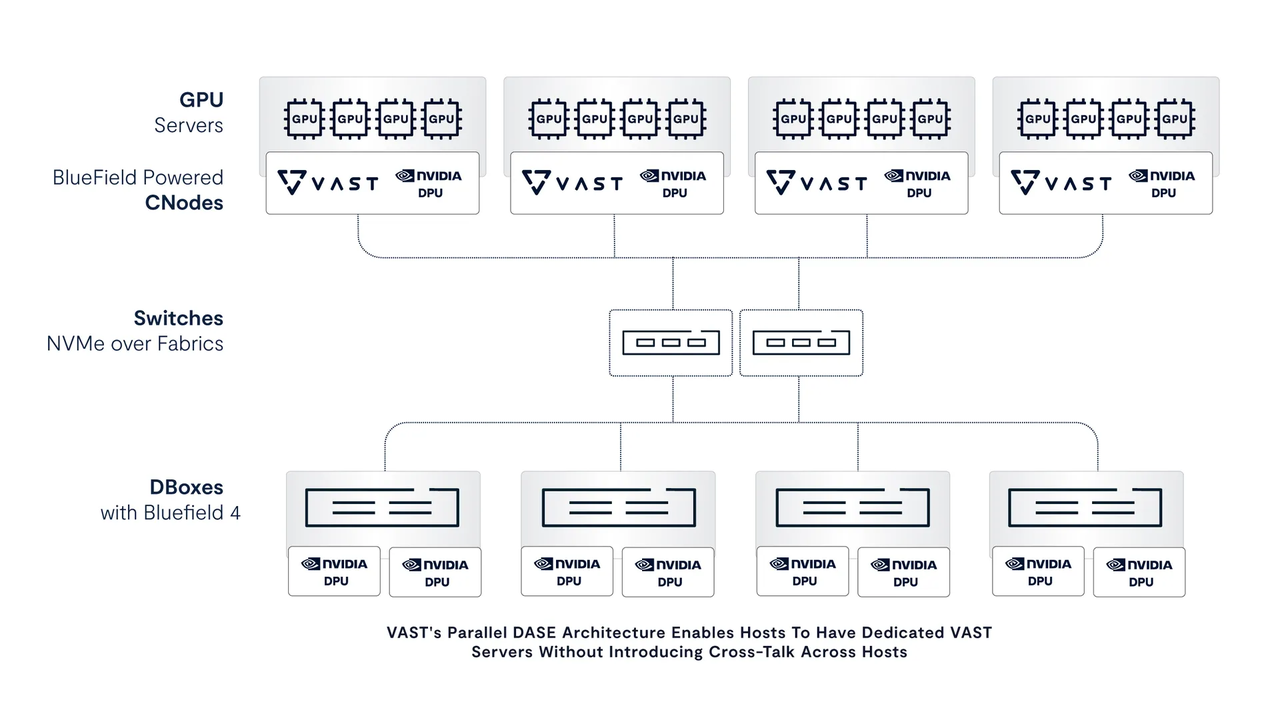
VAST 的并行 DASE 架构使各主机能够拥有专属的 VAST 服务器,同时避免主机之间产生相互干扰(跨主机串扰)。
VAST Data 的并行 DASE 架构在 BlueField-4 DPU 上运行控制逻辑,省去了服务器之间的东西向协调操作,同时允许每台主机并行访问所有固态硬盘。每个 DPU 都能直接访问完整的存储命名空间,即便推理并发量不断提升,也能为每台主机提供专属带宽,且不会产生任何干扰。
兼顾性能与数据服务,二者无需取舍
由于 KV Cache 数据具备易复制的特性,我们能够为 AI 实验室提供既能优化性能,且能支持各类数据管理工具的解决方案。
随着人工智能推理从探索阶段迈向规模化应用阶段,部分实验室必须构建符合强监管行业要求的服务。而借助 VAST Data 的方案,他们无需为追求极致性能而牺牲其他能力,还能启用一系列可选的数据服务,助力打造安全且可复现的人工智能系统。
我们可以预见,未来与英伟达 Dynamo 团队的合作中,Dynamo API 将能够指导推理上下文内存存储系统,在与共享服务交互时,针对不同数据集采取差异化的处理方式。
得益于 VAST Data 并行 DASE 架构支持带外添加更多 CNode 节点,即便推理 KV Cache 的并发量持续增长,推理历史数据依然能保持可访问性与全局可管理性。同时,该架构还能提供一套工具来运行后台服务,且不会重新引入那些 ICMS 平台原本旨在消除的数据管理开销。
BlueField-4 如何推动这场变革
ICMS 平台的架构设计,与英伟达 BlueField-4 DPU 的运行机制高度契合。
DPU 为全新的存储服务部署模式创造了可能。这款先进的数据处理器将加速计算核心直接集成在网卡上,在数据路径中直接充当数据放置、访问控制与验证的执行节点。通过在 BlueField-4 上以线速执行这些功能,主机 CPU 被移出了关键数据路径。现在,DPU 可通过共享的 NVMe-oF 网络,直接与存储机柜中的 NVMe 设备通信。
每次数据访问涉及的组件更少、状态转换次数更少,系统在负载下的运行表现也更加稳定可预测。
英伟达 Spectrum-X 如何推动这场变革
英伟达 Spectrum-X 以太网架构发挥着关键作用,它能为大型 AI 架构提供低延迟、高带宽的传输能力,同时具备拥塞控制与性能隔离功能。该平台作为更广泛的 Dynamo 推理编排框架的一部分,专为在 Spectrum-X 以太网架构上运行而设计,可在集群满负载持续运行时,提供稳定可预测的 KV Cache 服务。
跨部署模式的灵活性
该架构的优势并不局限于单一硬件形态。
早期部署可能会采用高密度、容错型 NVMe 存储机柜,以实现效率与空间利用率的最大化,但英伟达 ICMS 平台与 VAST Data 的架构理念,同样适用于基于通用存储服务器搭建的其他配置。
由于推理历史数据在全系统范围内共享,且访问控制在靠近 GPU 的位置执行,即使用户选择关闭纠删码功能,单台服务器发生故障时也不会触发全系统的上下文重建。
推理任务可继续使用剩余的分布式历史数据,避免了传统架构中节点故障后必然出现的大规模数据重建操作。
关键功能成效
这场架构变革带来的成效十分显著。
推理历史数据可作为共享系统资源被随时访问,无需经过性能受限的集中式存储服务器处理层。
由于访问决策与上下文检索在靠近执行端的位置完成,GPU 的利用率得到显著提升。由于每台 GPU 服务器都拥有专属的并行数据处理服务,系统并发能力实现了线性扩展。
由于整个方案针对端到端 KV Cache 服务进行了全面优化,系统的能效与基础设施空间利用率也随之大幅提升。
这些成效与英伟达 ICMS 平台所追求的核心目标高度契合,即:实现规模化场景下的持续吞吐量与高能效比。
一致性推理能力的跨越式提升
ICMS 平台将上下文历史数据定义为一级系统内存资源。英伟达 BlueField-4 在推理运行的边界,充当高效的存储控制器与数据放置、访问、隔离的执行节点;Spectrum-X 以太网提供稳定可预测的传输能力;Dynamo 则负责推理任务的编排调度。
VAST Data 则提供了核心软件层,将这些组件整合为一个统一协调的系统,确保即便上下文数据量、并发量与合规要求持续增长,推理历史数据依然能保持高可访问性、可管控性与高效性。
想了解这一方案的实际运行效果吗?
诚邀您参加在 1 月 27 日,由 VAST Data 与 英伟达联合举办的网络研讨会 ——《打破推理瓶颈:英伟达 KV Cache 与 VAST Data 如何为人工智能时代统一性能、扩展性与效率》,深入了解这一联合架构如何大幅提升 AI 推理速度、缩短首 token 响应时间、提高吞吐量,并降低大规模 GPU 部署的成本。
访问地址:
https://www.vastdata.com/events/breaking-the-inference-bottleneck-how-nvidia-kv-cache-and-vast-unify
