新闻动态
News


AI 工厂需要一条依赖高性能 GPU 与高性能存储的、不间断的生产线,其中数据是原材料,智能是最终产出。

AI 工厂需要基础设施、软件与人员协同运作,形成一套与传统甚至通用 IT 系统截然不同的体系。
随着云服务提供商(CSP)与新兴云厂商(neocloud)争相搭建由英伟达 HGX 及英伟达 GB200/GB300 NVL72 系统驱动的 AI 工厂,他们发现传统系统已完全无法跟上节奏。
AI 工厂需要一条依赖高性能 GPU 与高性能存储的、不间断的生产线,其中数据是原材料,智能是最终产出。
但所有云服务提供商都面临一个核心痛点:AI 流水线中传统的分层存储架构 —— 其单独的数据摄入、训练和归档形成了多个存储孤岛 —— 在万亿参数模型的重压下已然崩溃。
更雪上加霜的是,许多存储厂商仍在为文件存储(NFS)和对象存储(S3)分别提供不同的产品。
这给云客户带来了严重的碎片化问题。
使用 NFS 与 S3 的工作负载需要不同的端点、工具、安全控制、性能预期和生命周期管理方式。
企业无法拥有统一的、受管控的数据平面,反而要面对非标准化架构和孤立数据集,常常需要进行高昂的数据复制和抽取-转换-加载(ETL)操作,才能在高性能训练存储与用于数据摄入、共享和分析的数据湖存储(通常是 S3 桶)之间传输数据。
基于 VAST Data Ebox ,适用于英伟达 GB200 和 GB300 服务器的英伟达云合作伙伴高性能存储参考设计;
基于 VAST Data Ebox,适用于英伟达 HGX 服务器的英伟达云合作伙伴高性能存储参考设计。

人工智能基础设施正迅速从 GPU 集群向 AI 工厂转型(通常由 AI / GPU 云提供商托管)。
AI 工厂是将数据转化为智能的专用系统,贯穿整个 “数据摄入→训练 / 微调→部署大规模推理” 的全生命周期。
本质上,英伟达将 AI 工厂的产出定义为智能,其核心衡量指标通常是 token 吞吐量。
与此同时,从主流的 HGX GPU 服务器(H200、B200 和 B300)到英伟达 GB200 NVL72、GB300 NVL72 等机架级系统,云提供商的交付标准不断提高:更高的 GPU 密度与带宽需求、更宽的英伟达 NVLink 域(最多 72 块 GPU)、液冷机架级设计以及飙升的 FP4 性能。
所有这些都凸显了一个关键:数据平面是加速计算平台发挥人工智能性能的核心要素。
本文将深入剖析 AI 工厂时代 GPU 云客户的核心需求,并将这些需求与 VAST AI OS 的架构优势相对应 —— 该架构与适用于 HGX H200、HGX B200、HGX B300 部署以及机架级 GB200/GB300 NVL72 系统的英伟达云合作伙伴高性能存储参考设计保持一致。

客户使用 GPU 云时,购买的并非原始浮点算力,而是以符合业务需求的成本,快速、可预测地获得结果。在实际场景中,这一期望转化为一套明确、统一的平台需求:
1
适配不同 GPU 云场景的灵活构建模块
考虑到独特的功耗、机架空间和故障域(可用区)要求,GPU 云基础设施部署给数据中心运营商带来了新的挑战。
云服务提供商需要一个能适配所有场景的数据平台,而非针对每种拓扑结构使用不同产品。
VAST AI OS 基于 DASE(分解式全共享架构)构建,通过软硬件解耦解决了这一问题。
DASE 微服务既可以运行在独立的控制器节点和闪存介质节点上,也可以共存于同一台服务器,提供两种功能完全一致、可互换的部署选项:
C+D 模式(CNode + DBox):无盘 x86 架构 CNode 作为集群化 I/O 和管理层,独立的 DBox 提供高密度 NVMe 容量(适合需要独立扩展性能和容量的场景);
EBox 模式(集成式 C+D):EBox 将控制器与 NVMe 驱动器整合到单一 x86 设备中,为高性能存储设计(如英伟达 HGX 和英伟达 GB200/GB300 NVL72)提供极高的性能密度,同时减少机架空间占用、降低功耗和总体成本;该方案已有多家一线 OEM 企业可以提供。
由于 DASE 是软件架构,云提供商可根据站点或使用场景选择 C+D 或 EBox 模式,同时为所有 GPU 云客户提供统一、一致的 VAST AIOS 体验。
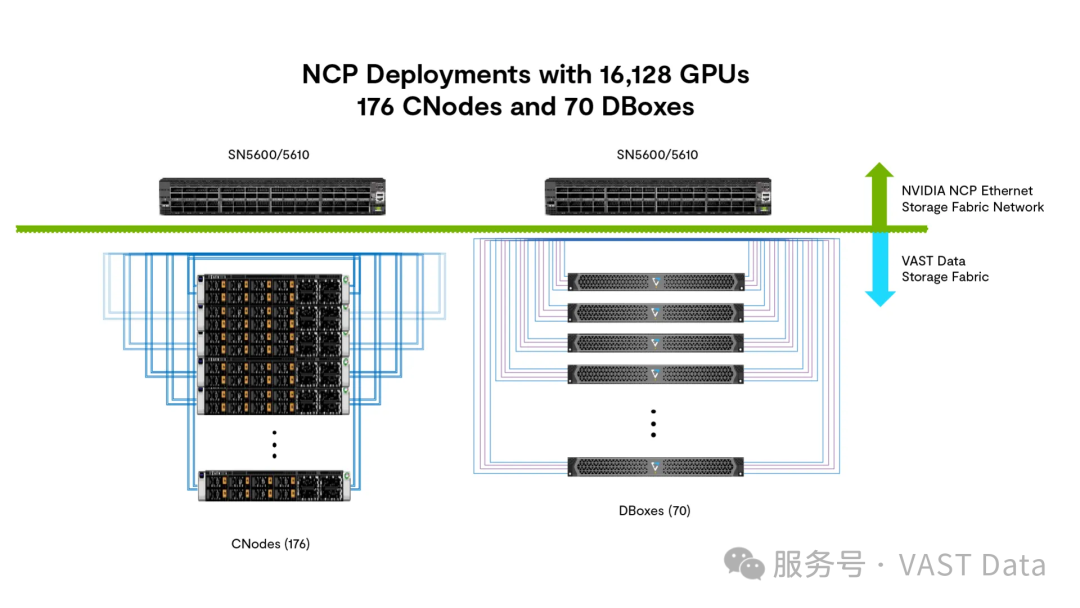
16,128 块 GPU 的 NCP 部署方案:176 个 CNode 和 70 个 DBox
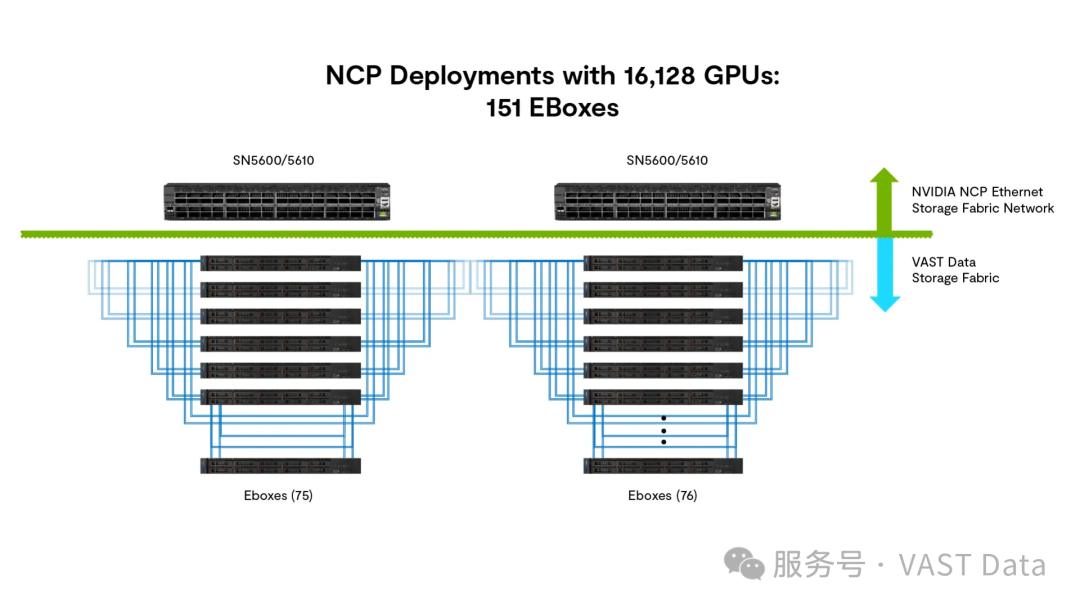
16,128 块 GPU 的 NCP 部署方案:151 个 EBox
2
为不可预测的工作负载提供可预测性能
AI 工作负载以突发性著称。一套可靠的高性能存储设计,必须优先保障训练所需的海量、持续读取吞吐量,同时高效处理周期性的检查点写入,避免 I/O 竞争导致 GPU 数据供应不足。
DASE 架构经过专门设计,可充分发挥 NVMe 闪存的性能潜力,通过 NVMe-oF(网络存储协议)和 RDMA 技术提供核心高速数据传输能力,确保 GPU 保持高利用率。
该平台支持 NFS 多路径、基于 NFS(v3/v4)的 RDMA 访问以及英伟达 Magnum IO™ GPUDirect™技术,单个挂载点即可提供 TB/s 的吞吐量,确保训练、微调与推理流程不会因等待数据而停滞。
3
快速检查点 + 稳健恢复
现代训练流程依赖频繁的检查点机制 —— 由步骤/迭代、Epoch 边界或基于时间的策略触发,支持同步和异步检查点 I/O。
客户需要快速、可靠且干扰最小的检查点,同时需要快速恢复能力,确保任务在故障或维护事件后数分钟(而非数小时)内即可恢复运行。
为满足现代训练对 I/O 的密集需求,VAST Data 借助 NFS 多路径、RDMA 和英伟达 Magnum IO GPUDirect 技术,实现 TB/s 的吞吐量,确保频繁的检查点操作不会限制 GPU 利用率。
该性能与智能数据管理相结合,将检查点视为受管控的资产,使机器学习运维(MLOps)团队能够追踪数据谱系,并从精确时间点快速恢复训练流程。
4
安全多租户,无 “邻居干扰” 代价
为满足企业对严格隔离和可预测性能的需求,VAST AIOS 采用了稳健的零信任框架,打破了安全性与租户密度之间的传统权衡。
该解决方案通过为每个租户分配专属 VIP 池,并结合 VLAN/VRF 分段,实现硬性网络隔离,确保数据流量在整个架构中完全隔离。
此外,精细化的服务质量(QoS)策略和租户专属配额设置,能有效防止 I/O 竞争,确保单个工作负载的突发活动不会影响其他租户的性能。这使得云服务提供商能够最大化基础设施利用率,同时为每个租户提供安全隔离的环境、专属加密密钥和专用目录层级。
5
打破协议壁垒:单一数据集,多类消费者
实际应用中的 AI 流程常因存储孤岛而碎片化,迫使数据工程师在用于摄入的对象存储和用于训练的文件系统之间复制数据。
VAST AI OS 支持对统一命名空间的多协议访问 ——NFS、SMB、S3 和 英伟达 Magnum IO GPUDirect Storage(GDS),彻底消除了这一低效问题。
数据可通过 S3 摄入,借助高性能文件访问进行预处理,并由 Spark 或 Trino 等 SQL 引擎进行分析,全程无需移动数据。
在 VAST Catalog 的支撑下,所有文件和对象都会被自动索引,确保在所有数据消费者和流程的各个阶段,都能实现一致的治理、谱系追踪、高速元数据查询和可审计性。
6
深度可观测性
在多租户 AI 云中,性能缓慢的原因往往难以排查。为避免网络、计算和存储团队之间相互推诿,VAST Management System(VMS)提供深度、持续的可观测性,相当于云基础设施的性能飞行记录仪。
VMS 摒弃了掩盖根本原因的聚合指标,提供实时用户活动视图,精准定位生成负载的具体任务、用户或客户端 —— 不仅能识别 “干扰性租户”,还能找出导致 I/O 饱和的具体数据消费者。
这使得平台团队能够将存储行为(延迟、IOPS、吞吐量)与机器学习事件(如检查点突发、评估扫描或推理峰值)直接关联。
通过将模型制品和中间检查点列为一等受管控资产,运维人员可立即判断系统停滞是源于批量特征提取,还是意外的数据导出,从而快速采取补救措施,并严格执行公平使用政策。
7
融合网络架构
VAST AIOS 遵循英伟达融合网络设计,采用英伟达 Spectrum™ SN5600/SN5610 叶交换机,无需单独部署带内管理和存储架构。
在该架构中,前端(客户端访问)和后端(内部存储)流量共享同一高带宽、支持 RDMA 的以太网叶层。这种融合方案大幅降低了布线复杂性和交换机冗余,同时通过 VLAN 分段(如内部通信与客户端访问分离)和基于差分服务代码点(DSCP)的优先级流控制(PFC),确保严格的性能隔离和无丢包传输。

AI 工厂需要专用数据基础设施。通用云存储无法让英伟达 GB200/GB300 NVL72 机架服务器保持满负荷运行,以满足服务等级协议(SLA)。VAST Data 与 英伟达 Reference Design 的合作,可以为云服务提供商带来三大明确优势:
规模化验证:支持从约千卡到 4 万卡以上 GPU 的扩展,尺寸经过预先验证。EBox(或 C+D)与 GPU 的配比已通过英伟达测试验证,因此云服务提供商可放心部署 VAST Data 作为高性能存储方案;
企业级 SLA:架构设计支持六个九(99.9999%)的可用性和硬性多租户隔离,云服务提供商可放心为核心企业客户和原生 AI 客户提供高端 SLA;
运维简化:用统一的数据平台替代碎片化的存储层级(数据湖、归档、闪存高速临时存储)。无需再依赖脆弱的数据迁移脚本,无需再支付数据复制成本;仅需一份受管控的数据集,即可支撑所有人工智能流程。
准备好构建你的 AI 工厂了吗?
如需了解 VLAN 配置、布线图以及适用于英伟达 GB200、GB300 和 HGX 服务器的具体尺寸表等更深入的技术细节,请查阅 VAST Data NCP 高性能存储参考设计完整文档 —— 该文档基于我们与 OEM 合作伙伴联合推出的 EBox 设计。
本文作者:
VAST Data 人工智能解决方案工程总监 Prasad Venkatachar
VAST Data 售前技术总监 Ray Coetzee
