新闻动态
News


做AI推理的伙伴们看过来!最近我们容天AI实验室完成了Qwen3.6 NVFP4在2×NVIDIA RTX PRO 5000 Blackwell硬件上的全面推理测试。
结果直接刷新预期——单流速度比FP16方案快9倍,峰值吞吐突破4000 tok/s,看完这份实测总结,你再也不用为推理性能选型发愁~

先上核心结论,帮大家快速抓重点:
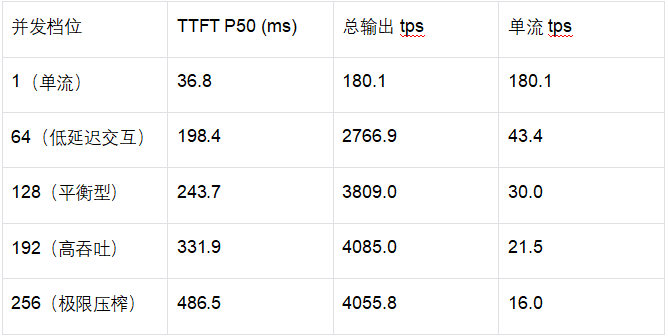
单流首包延迟低至38.3ms,输出速度达180 tok/s,交互体验拉满;
峰值吞吐4085 tok/s,高并发能力拉满;
并发192达性能拐点,兼顾吞吐与延迟,部署选型有明确方向;
长上下文表现优秀,16K prompt仍能稳定运行,适配多场景需求。
核心测试环境(必看!):
硬件:2×NVIDIA RTX PRO 5000 Blackwell
模型:Qwen3.6 NVFP4(量化格式:compressed-tensors / nvfp4-pack-quantized)
环境:Ubuntu 24.04 + Docker(vllm/vllm-openai:cu130-nightly)
服务配置:TP=2,max_model_len=131072,gpu_memory_utilization=0.85
结合测试结果,整理了4种部署模式,直接对照选用即可,不用再自己摸索:
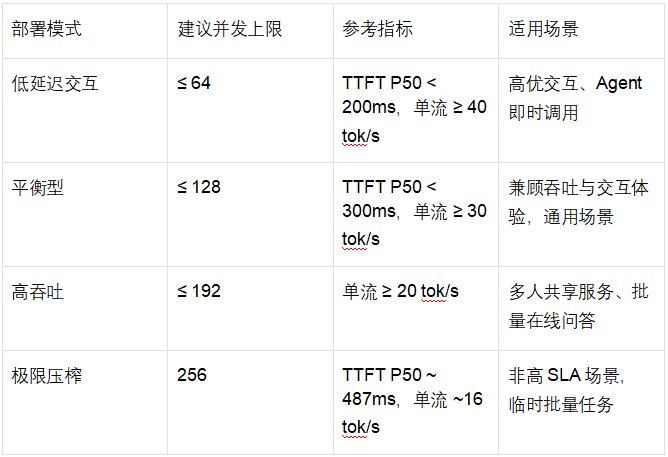
本次测试全程零失败,综合来看,2×RTX PRO 5000 Blackwell + Qwen3.6 NVFP4的组合,核心优势总结3点:
性能能打:硬件潜力充分释放;
部署灵活:不同并发档位对应不同场景,从低延迟交互到高吞吐批量任务,全覆盖无死角
运行稳定:GPU负载健康,长上下文表现优秀,适配绝大多数AI推理业务场景
如果你的业务涉及AI推理、大模型部署,这套组合值得重点考虑~
后续我们还会持续更新更多模型+硬件的实测报告,记得关注不迷路!