新闻动态
News


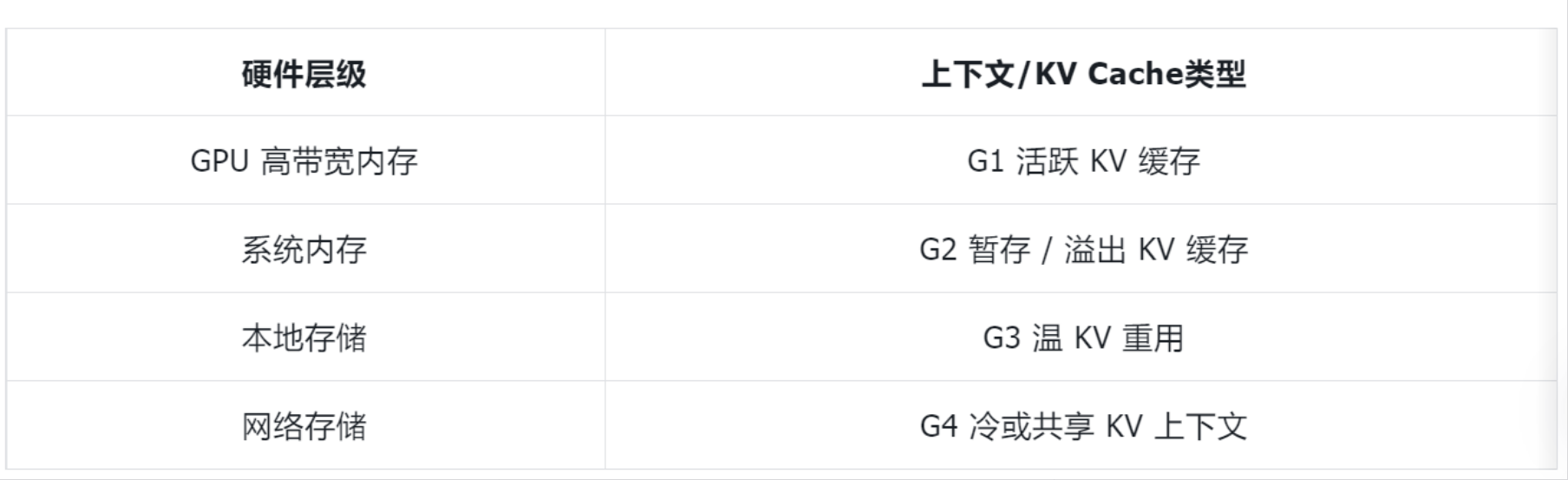
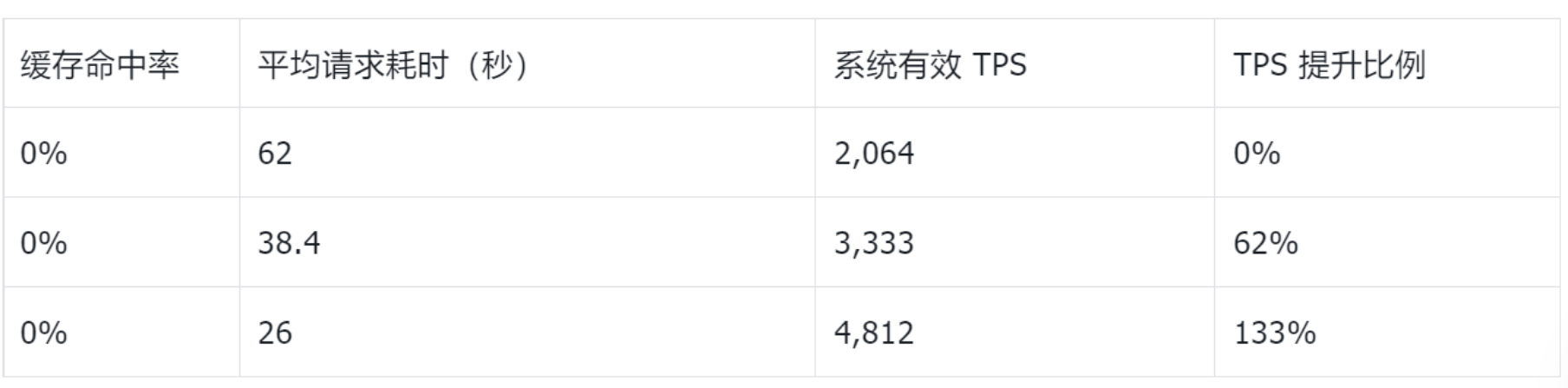
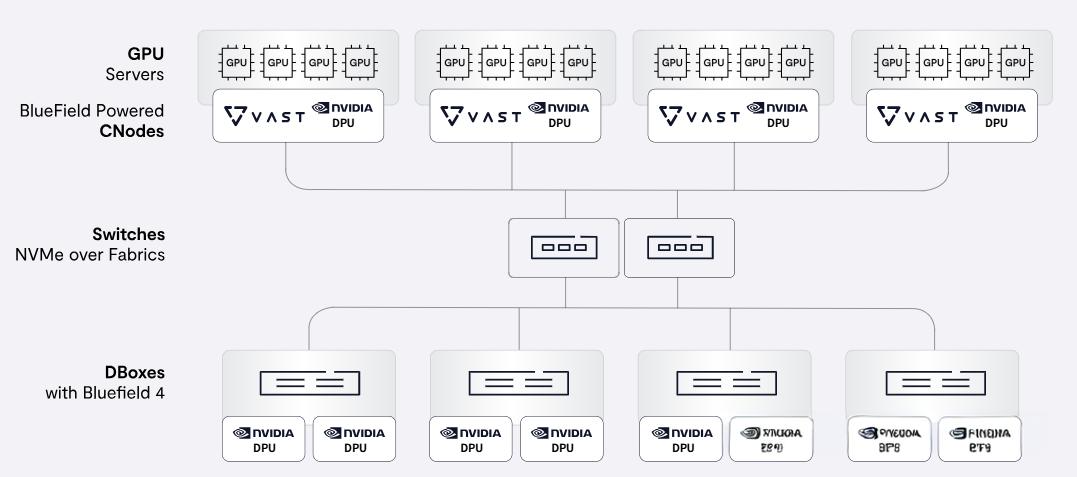
实际上,KV cache 已演变为长效内存,系统性能取决于 KV cache 的管理效率与上下文复用能力。推理上下文离 GPU 越远,推理成本就越高,运行效率也越低。

尽管人们的关注点似乎一直聚焦在算力扩容上,但在实际的大规模 AI 应用场景中不难发现,这种认知正迅速被打破。 当系统需要满足未来核心工作负载 —— 例如持续为线上用户提供服务、在多次交互中留存上下文、运行超长任务流程时,单纯依靠算力扩容的思路便不再适用。 行业关注点正在快速转变:从之前的单纯追求模型运行速度,转变为密切考虑“系统如何能在不触及内存瓶颈的情况下,长时间维持有价值的交互”。 在 VAST Forward 2026 大会上,VAST Data AI 架构总监 Anat Heilper 向参会者表示,性能瓶颈已不再局限于算力,内存管理成为新的挑战。“我们发现行业正在发生转变,对话的上下文(Context)已经变得与模型本身同等重要。”她解释道,这一转变也要求业界采用全新的系统设计方案。 与模型训练不同,生产环境的推理服务(Production inference)需要不间断运行、并行服务大量用户,并完整留存每一次交互记录。这些记录累积形成上下文数据,进而推高内存需求。系统设计的重心不再是运算能力,而是如何高效存储、调取在这些交互过程中产生的信息。 Heilper 表示,这正是“GPU 内存墙(GPU memory wall)”所形成的现实难题的原因。GPU 内存读写速度快,但容量有限,一旦上下文数据超出容量上限,就必须流转至系统其他存储层级。数据每远离 GPU 一层,延迟与使用成本都会随之增加。她强调,此时系统面临的核心考验,是如何在不降低整体运行效率的前提下,保障上下文数据可被快速调用,充分发挥 Token 的处理价值。 英伟达高级研究员 Vikram Sharma Mailthody 同台分享,与 Heilper 深入探讨了一个问题:当推理不再是简单的请求-响应循环,而演变成一个持续过程时,系统会发生什么变化。 Mailthody 称,智能体系统不只是简单回应提示词,还会执行多步骤任务、调用各类工具,循序渐进达成业务目标。而这一切得以实现的前提,是上下文数据持续留存,而非单次响应后便清空。 “推理服务已不再是无状态运行。智能体需要在跨交互、跨会话、跨历史记录乃至跨服务的场景中,留存并复用上下文数据。” 他补充道,这意味着上下文数据已然成为负载中需要长期保存的内容,在跨会话、跨服务流转的同时,还要确保系统处理每一个步骤时都能随时调取。 这就导致系统需要管理的上下文数据量持续上涨,更长的文本序列、工具输出数据以及多用户并发访问,都会进一步推高这一数据规模。 推理上下文已成为全新的瓶颈 存储架构必须重新设计 推理上下文数据量大、动态变化且支持重算 上下文数据必须能在 GPU 与节点间共享 本地内存存在固有限制 传统存储扩容会推高成本与功耗 高效的上下文扩容需要全新的架构设计 随着上下文数据不断增加,KV cache 成为系统的核心管理目标。这并非易事。KV cache 用于存放注意力数据,避免重复运算,而长文本序列与高并发场景会让其容量快速膨胀,如今它已是内存资源的主要消耗项之一。 此时,KV cache 承担起工作内存(Working Memory)的作用,保障多轮交互逻辑连贯。Mailthody 解释道:“实际上,KV cache 已演变为长效内存,系统性能取决于 KV cache 的管理效率与上下文复用能力。推理上下文离 GPU 越远,推理成本就越高,运行效率也越低。” 自此,系统瓶颈不再是运算速度,而是能否让上下文数据就近存储、随时可用,这也让 VAST Data 与英伟达的技术协同优势得以充分发挥。 当 KV cache 成为核心后,如何在全系统内对其进行调度管理就成了关键,英伟达 Dynamo 便承担起这一推理编排工作。 它作为推理调度层,负责规划请求处理方式、任务运行节点以及上下文复用策略。该组件将推理流程拆分为多个协同模块:API 层接收请求,路由模块根据 KV cache 分布位置分发任务,规划模块则根据负载变化动态调整资源配额。 在这些组件之下,KV cache 管理器实时追踪上下文数据在各级内存中的分布位置,数据传输层负责在 GPU、内存与存储设备之间流转数据。 计算密集型的预填充阶段与内存密集型的解码阶段可拆分独立运行,并分别完成性能优化,这一设计进一步完善了智能内存管理机制。系统可自主选择最优运行路径,路由调度不再单纯依靠负载均衡,还会结合上下文数据的存储位置综合判断。 最终,推理服务呈现出分布式系统的运行特征,请求、内存与算力资源始终保持协同调度,实现大规模场景下的上下文复用。但新的问题也随之显现:即便具备完善的编排能力,系统性能依旧取决于上下文数据的读写速度。 一旦任务编排工作就绪之后,下一道性能瓶颈便是上下文数据的读取与复用速度,而这正是 VAST Data 的技术优势所在。 KV cache 不同于普通数据,具备读密集、大块读取、高频复用的特点。VAST Data 的架构恰好适配这类访问模式,将原本可能出现的 I/O 瓶颈转化为可随网络带宽线性扩容的能力。 Heilper 表示:“我们并非提升 GPU 本身的运算速度,而是提高 GPU 的有效利用率,让存储成为算力的增效引擎。” 依托高速读取 KV cache 来规避重复计算,GPU 能够持续处理全新任务,而非反复重构上下文数据。 优化效果十分显著。她说道:“原本需要 GPU 耗时 65 秒完成计算的任务,如今仅需 3 秒即可读取缓存数据完成处理,这是质的改变。” 该优化大幅减少 GPU 资源浪费,在硬件不变的情况下,有效提升响应速度与整体处理能力。 此时,存储不再只是单纯承载数据,而是直接提升整套系统的算力产出能力。 Heilper 提到,这种改进取决于系统重用上下文而非重建上下文的频率。在实际业务中,缓存命中率普遍可达 40% 至 60%,仅这一项就能显著提升系统整体产能。 VAST 效应:每美元可处理 Token 数提升 60%-130% Assumptions:(假设条件) 缓存命中率:40%-60% 预填充耗时:无 KV cache 复用为 62 秒,使用 KV cache 复用为 3 秒 测试配置:Llama 3 405B 模型,128K 上下文,8 张 H100 GPU,2×100Gb/s 网络带宽 依托这样的复用效率,系统整体吞吐量大幅提升,单位成本可处理的 Token 数量提升约 60% 至 130%。性能增益的核心,是让算力专注于全新任务,而非重复执行已有运算。 当 KV cache 脱离 GPU 后,它便不再只是影响性能的临时数据,而是正式成为业务数据。其中包含指令、用户输入内容以及模型运算的中间结果,在生产环境中属于敏感数据。 Anat Heilper 解释道:“KV cache 一旦转出 GPU,其中包含的用户敏感数据就有可能遭到篡改或逆向破解。” 这意味着上下文数据不能再被当作临时数据对待,必须像核心业务数据一样做好安全防护与规范管理。 这就要求数据满足企业级管控标准:数据加密、用户数据隔离、精细化权限控制。由于上下文数据会跨会话长期留存,数据留存策略也至关重要。多用户、多服务共享一套基础设施,更需要统一的数据治理体系。 在此场景下,VAST Data 的能力不再局限于性能优化,还可为 KV cache 提供全套企业级数据服务,兼顾运行效率与安全管控。当推理业务落地至合规监管类场景时,这一能力已成为系统设计的核心组成部分。 即便搭配完善的任务编排与高速存储,KV cache 的数据量仍在持续增长。若将大量数据存入传统存储,会进一步增加延迟与使用成本。为此,英伟达推出专为推理场景打造的全新内存层级 CMX。 CMX 部署在 GPU 内存与存储设备之间,可在同一计算集群(Pod)内的多块 GPU 间共享资源。该层级支持上下文数据复用,无需重复拷贝,既能让更多工作内存靠近 GPU 以保障性能,又能突破 GPU 物理内存的容量限制。 该内存层级依托 BlueField-4 DPU 与高速网络实现能力落地。BlueField-4 将算力与数据服务下沉至推理侧,支持 VAST Data 直接运行在 DPU 之上,精简服务器层级,加速 KV cache 在 GPU 与存储之间的数据流转。 在大规模应用场景中,这套架构价值凸显。承载数千用户的系统,需要数百 TB 空间存放活跃上下文,还需数 PB 空间实现跨会话数据留存。该架构可在扩容容量的同时,保证数据访问速度,让长会话任务与常驻智能体稳定运行。 最终,整套系统以内存为核心进行架构设计,算力、存储、网络协同配合,保障上下文数据随时可用、可复用。而这也成为决定系统整体业务承载力的核心因素。