新闻动态
News


大家好!在AI应用落地过程中,容天AI实验室大模型推理加速与智能体联动是实现人机交互、机器人服务、问答系统的两大核心环节。今天为大家带来一套完整的生产级部署方案:基于4卡NVIDIA RTX PRO 5000 Blackwell服务器,完成Qwen3.6-35B-A3B-NVFP4量化模型、vLLM推理服务与Hermes Agent智能体的联合部署,并结合全维度压测数据,分享适配Hermes交互场景的最优配置、并发策略与运维方案,无论是搭建微信机器人、在线问答还是智能工具调用场景,都可以直接参考复用。

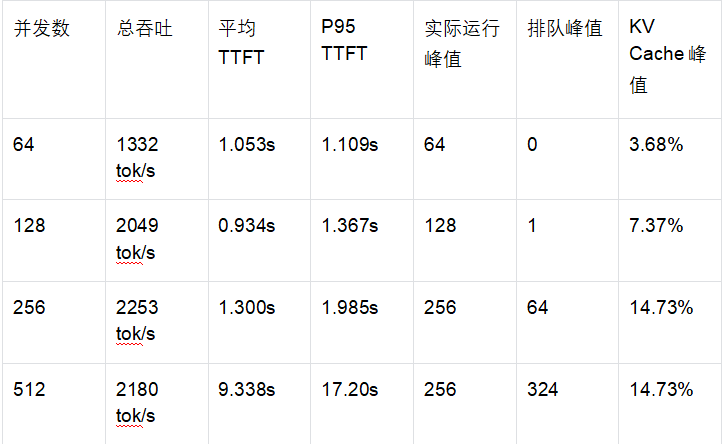
本次部署,整套架构采用vLLM作为底层推理引擎,承载Qwen3.6 NVFP4量化模型,对外提供标准OpenAI格式API;上层对接Hermes Agent v0.14.0智能体,实现工具调用、对话管理、多轮交互等能力,整套服务已配置容器开机自启,可7×24小时稳定运行。 核心能力亮点 超大上下文支持 模型最大上下文长度131072 tokens,轻松处理超长文档解析、万字对话、长文本问答等场景; 极致推理性能 单并发推理速度可达185-197 tok/s,短上下文吞吐峰值2253 tok/s; 全链路兼容 vLLM原生兼容OpenAI API,Hermes无缝对接,支持工具调用、流式输出; 量化优化 采用NVFP4量化格式,模型体积仅22G,4卡张量并行充分释放RTX PRO 5000算力; 灵活并发策略 区分在线交互、后台批处理两大场景,提供不同并发阈值,兼顾响应速度与算力利用率。 硬件配置 本次使用4张NVIDIA RTX PRO 5000 Blackwell显卡,单卡显存48935 MiB,整机采用x86_64架构,为大模型并行推理提供充足算力与显存支撑。 宿主机必备组件 部署前需完成基础环境安装,适配Docker容器化部署与Python环境,Ubuntu/Debian系统可直接执行下方命令一键安装: bash 核心依赖说明: Docker + NVIDIA Container Toolkit:支撑vLLM容器运行,打通GPU虚拟化调用; Python3+虚拟环境:用于Hermes Agent的安装、运行与版本隔离; curl/jq:用于API接口调试、指标监控与JSON数据解析。 容器镜像选型 vLLM采用官方nightly镜像,兼顾新特性与稳定性,同时留存多个备用镜像应对版本切换需求: 主力运行镜像:vllm/vllm-openai:nightly 备用镜像:vllm/vllm-openai:cu130-nightly、vllm/vllm-openai:latest Qwen3.6-NVFP4 模型信息 模型存放路径:/model/qwen3.6-nvfp4,整体大小22G,采用ModelOpt NVFP4量化,包含完整的权重分片、分词器、聊天模板与工具调用配置,完美适配Qwen系列工具解析规则。 核心文件包含模型权重分片、量化配置、分词器、对话模板等,无需额外修改即可加载运行。 vLLM 服务部署(核心推理层) (1)当前运行参数(临时启动) 容器名称:vllm-server,启用4卡张量并行,开启前缀缓存、分片预填充、自动工具选择等优化功能: bash (2)生产环境推荐启动命令(重点!适配Hermes交互) 相较于临时参数,生产版本新增最大并发序列限制、全局关闭思维链输出,彻底解决Hermes调用时出现多余thinking文本的问题,同时保留容器自启策略: bash 自启策略:unless-stopped,服务器重启后自动拉起服务; 关键新增参数:--default-chat-template-kwargs 全局关闭模型思维输出,统一Hermes对话格式。 Hermes Agent 配置(智能体交互层) Hermes作为上层智能体,负责对话逻辑、工具调度、多轮会话管理,是对接微信机器人、在线问答的核心入口。 安装信息 安装目录:/opt/hermes-env 命令软链接:/usr/local/bin/hermes、/usr/local/bin/hermes-agent 版本:Hermes Agent v0.14.0,Python 3.12.3,OpenAI SDK 2.24.0 核心配置文件 配置文件分root用户与普通用户两套,统一指向本地vLLM API地址,配置路径: root用户:/root/.hermes/config.yaml 普通用户:/home/lyl/.hermes/config.yaml 标准配置内容(直接复制使用): yaml 服务验证命令 bash 为了匹配Hermes不同业务场景,我们完成了常规生成、长上下文、极限并发三大类测试,所有测试均关闭模型思维输出、启用流式请求,数据真实反映生产环境表现。 基础推理性能 单并发推理速度:185-197 tok/s,短文本响应极快; 固定512 Token输出场景:单请求平均速度稳定在196 tok/s左右; 代码生成场景:单并发512 Token输出耗时2.979s,推理表现优秀。 长上下文测试(核心优势) 模型131072 tokens超大上下文已完全生效,可稳定处理超长文本输入,受前缀缓存优化影响,超长文本推理效率进一步提升: 小贴士:长上下文场景下,单个请求占用KV Cache会大幅提升,并发上限需主动降低,避免排队超时。 极限并发压测 (关键!决定Hermes业务并发阈值) 测试档位覆盖1~512并发,每请求固定输出128 Token,统计吞吐、首Token延迟(TTFT)、排队数、KV Cache使用率等核心指标,整理关键数据如下: 并发瓶颈总结 KV Cache并非短文本瓶颈:短上下文压测中KV Cache峰值仅14.73%,瓶颈集中在GPU解码吞吐、请求调度队列; 有效并发上限256:256并发达到吞吐峰值,512并发时请求开始大量排队,吞吐不升反降; 高并发严重影响交互体验:512并发下P95首Token延迟高达17.2s,在线对话会出现明显卡顿。 结合压测数据,针对Hermes对接的在线交互与后台批处理两大核心场景,给出明确的并发配置建议,直接落地即可: 场景一: Hermes交互 / 微信机器人 / 在线问答(推荐) 建议并发:64 ~ 128 优势:首Token延迟基本可控、几乎无排队,用户交互体验流畅稳定; 配套参数:vLLM启动参数设置 --max-num-seqs 128; 适用场景:个人微信机器人、公众号AI对话、实时在线问答、多轮闲聊、工具调用交互。 场景二: 后台批处理 / 离线生成 / 文档批量解析 建议并发:256 优势:整机吞吐拉满(峰值2253 tok/s),最大化利用4卡GPU算力; 配套参数:vLLM启动参数设置 --max-num-seqs 256; 适用场景:批量文案生成、离线文档总结、知识库批量录入、数据清洗、非实时批量推理任务。 API接口调试(快速验证服务可用性) 查看已加载模型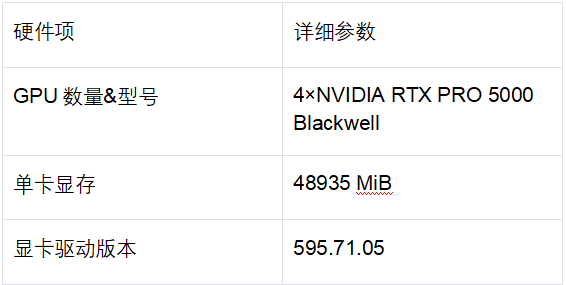
apt update
apt install -y \
openssh-server \
curl \
ca-certificates \
gnupg \
python3 \
python3-venv \
python3-pip \
jq \
git
vllm serve /model/qwen3.6-nvfp4 \
--port 8000 \
--tensor-parallel-size 4 \
--trust-remote-code \
--dtype auto \
--quantization modelopt \
--gpu-memory-utilization 0.90 \
--max-model-len 131072 \
--enable-chunked-prefill \
--enable-prefix-caching \
--enable-auto-tool-choice \
--tool-call-parser qwen3_xml \
--host 0.0.0.0
docker rm -f vllm-server
docker run -d --name vllm-server \
--restart unless-stopped \
--gpus all \
--network host \
--ipc=host \
--privileged \
-v /model:/model:ro \
vllm/vllm-openai:nightly \
/model/qwen3.6-nvfp4 \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 4 \
--trust-remote-code \
--dtype auto \
--quantization modelopt \
--gpu-memory-utilization 0.90 \
--max-model-len 131072 \
--max-num-seqs 256 \
--enable-chunked-prefill \
--enable-prefix-caching \
--enable-auto-tool-choice \
--tool-call-parser qwen3_xml \
--default-chat-template-kwargs '{"enable_thinking": false}'
model:
default: /model/qwen3.6-nvfp4
provider: custom
base_url: http://127.0.0.1:8000/v1
api_key: none
context_length: 131072
max_tokens: 8192
onboarding:
seen:
busy_input_prompt: true
tool_progress_prompt: true
# 查看Hermes版本
hermes --version
# 启动Hermes交互终端,验证连通性
hermes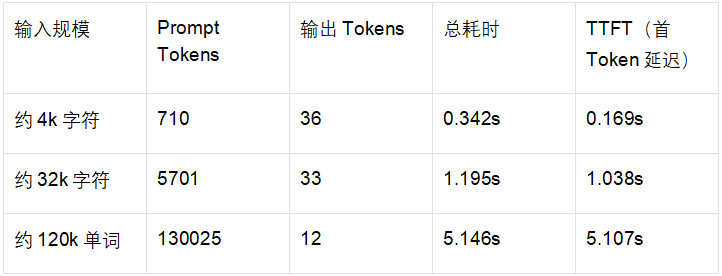
bash |
对话接口测试(模拟Hermes调用)
bash |
监控vLLM核心指标(KV缓存、Token统计)
bash |
核心指标释义:
vllm:num_requests_running:当前正在运行的请求数
vllm:num_requests_waiting:排队等待的请求数
vllm:kv_cache_usage_perc:KV缓存使用率
日常运维常用命令
bash |
这套Qwen3.6-NVFP4 + vLLM + Hermes Agent 组合,基于4卡RTX PRO 5000 Blackwell服务器完成全链路部署,完美兼顾高速推理、超大上下文、智能体交互三大核心能力,经过多轮极限压测验证,完全满足生产环境落地要求。 针对Hermes智能体+微信机器人场景,我们提炼出核心落地准则: 在线实时交互:极致平衡延迟与稳定性; 对于预算有限、缺乏专业AI运维团队的中小企业而言,这套 Qwen3.6-NVFP4 + vLLM + Hermes Agent 私有化部署方案,摒弃了公有云大模型的高额调用费用、数据泄露风险,依托4卡服务器即可实现全员本地化AI办公,覆盖企业日常办公、客户服务、内容生产、文档处理等核心刚需场景,实用性极强。 企业微信/公众号智能客服 依托Hermes Agent智能交互能力,搭建企业专属AI客服,对接企业微信、微信公众号、官网咨询窗口。基于模型131072超大上下文,可一键学习企业产品资料、售后手册、常见问答、企业文化,实现7×24小时无人值守自动答疑、客户咨询分流、售后问题预处理。搭配64-128稳定并发,可满足企业日常客户咨询峰值,低延迟响应不卡顿,大幅减少人工客服工作量,降低企业人力成本。 办公文档批量处理 适配中小企业行政、运营、财务岗位日常办公需求,依托256高吞吐并发能力,实现离线批量办公任务。可自动完成合同审核、简历筛选、公文改写、周报月报批量生成、长文档总结、会议纪要提炼、规章制度整理等工作。超大上下文支持直接解析万字合同、长篇报表、完整项目文档,无需拆分文本,批量处理效率远超人工,大幅提升办公效率。 企业内容营销自动化生产 助力中小企业新媒体运营、品牌推广工作,可批量生成公众号推文、短视频脚本、产品宣传文案、朋友圈文案、活动策划方案、客户回访话术。依托模型优秀的文本生成与逻辑能力,生成内容贴合企业品牌调性,同时支持自定义风格、语气、格式,批量并发生成模式可一次性产出多篇营销内容,解决中小企业运营人员不足、内容产出效率低的痛点。 内部智能问答知识库 搭建企业私有化专属知识库,录入企业制度、考勤规则、岗位职责、项目资料、培训文档、客户档案等内部资料,员工可随时通过Hermes智能体快速问答,自助解决办公疑问、查阅业务资料、学习岗位技能。私有化本地部署,所有企业核心数据不外泄,彻底规避公有云AI的数据安全风险,适配涉密办公、商务资料留存场景。 轻量化代码辅助与办公工具调用 模型自带优质代码生成与工具调用能力,可满足中小企业简易开发、办公脚本编写需求,自动生成Excel处理脚本、数据统计脚本、简易自动化工具,助力办公数据整理、报表自动化统计。无需专业开发人员,即可实现办公流程轻量化自动化,适配小微企业数字化转型刚需。